Extending MPI for Big Data with Key-Value based Communication
Performance
-
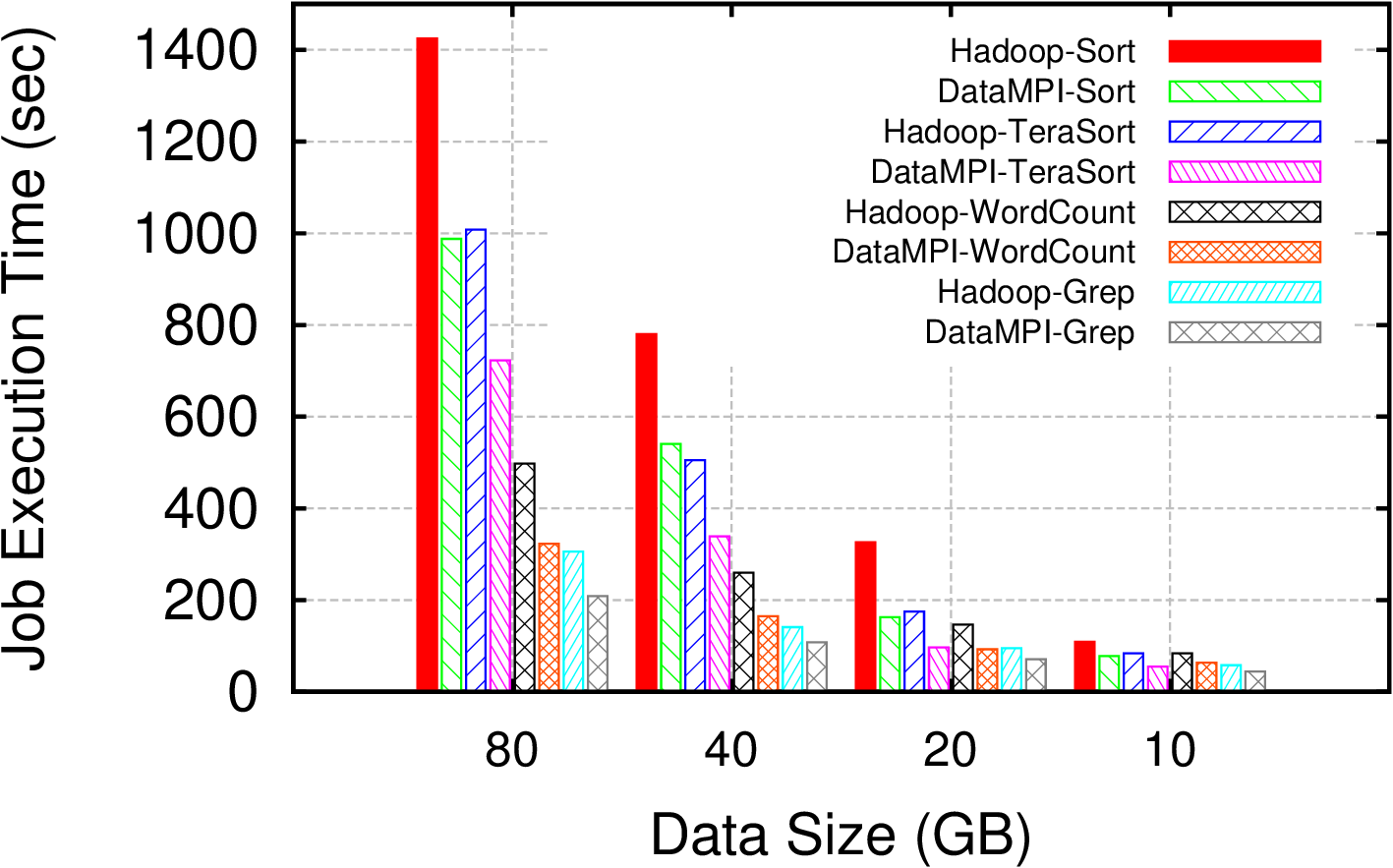
Experimental Testbed: This testbed has 8 nodes. Each node has two 4-core Intel Xeon 2.4 GHz processors, 16GB memory, one 250GB SATA disk, and one 1GigE card. Each node runs CentOS 6.4 x86_64.
-
Configuration: Hadoop version is 1.2.1. The backend MPI is mvapich2-2.0b. Hadoop benchmarks are the native examples. The version of DataMPI benchmarks is 0.6.0. Input/Output data sets are stored on HDFS. The HDFS block size is 256 MB and the replication factor is 3. Each node runs 4 O/A (or Map/Reduce) concurrent tasks for DataMPI (or Hadoop).
-
Result: Compared with Hadoop, the performance improvement of DataMPI ranges from 24% to 53%.
-
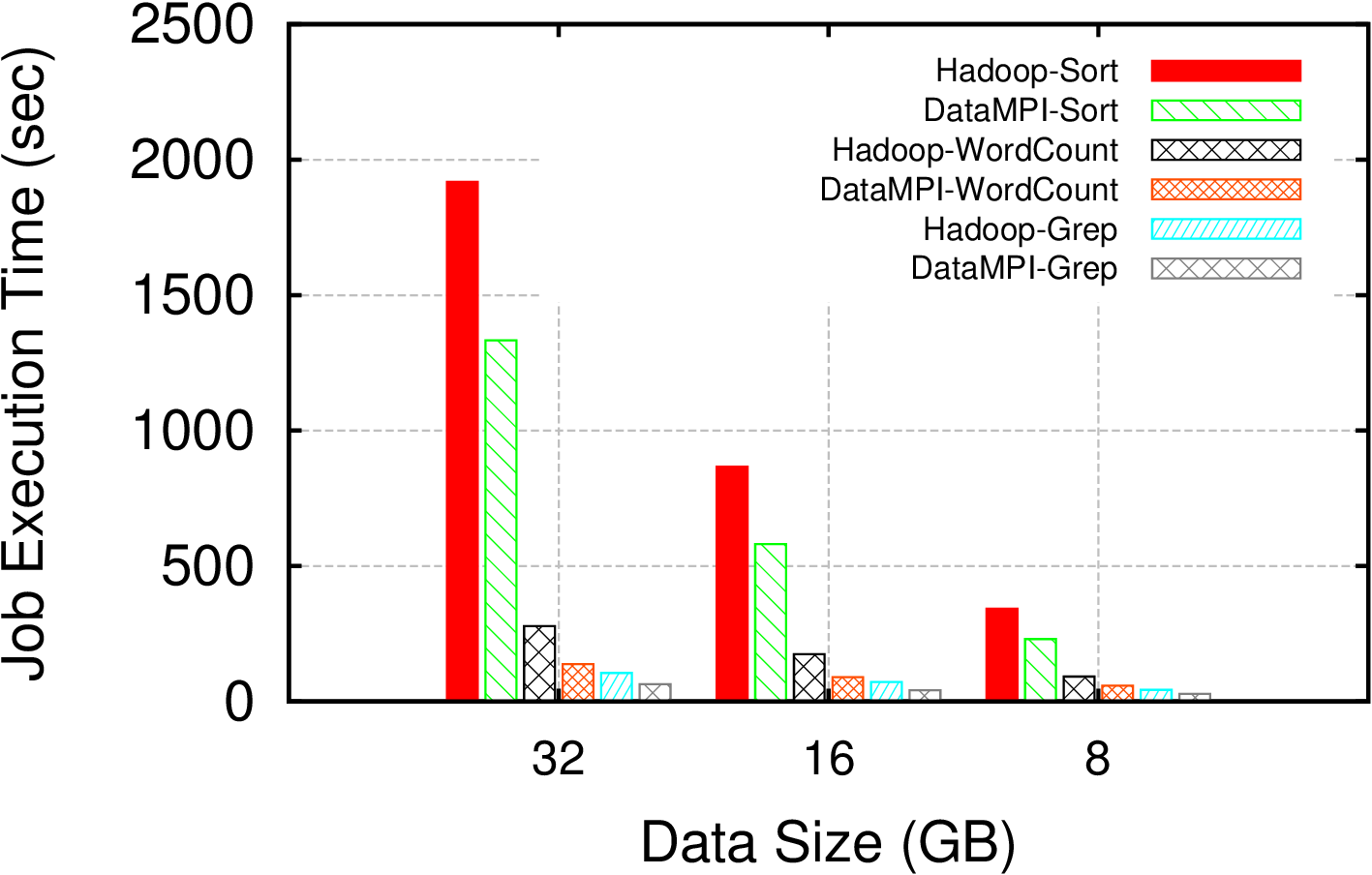
Experimental Testbed: This testbed has 8 nodes. Each node has two 4-core Intel Xeon 2.4 GHz processors, 16GB memory, one 250GB SATA disk, and one 1GigE card. Each node runs CentOS 6.4 x86_64.
-
Configuration: Hadoop version is 1.2.1. The backend MPI is mvapich2-2.0b. Hadoop benchmarks are the native examples. The version of DataMPI benchmarks is 0.6.0. Input/Output data sets are stored on HDFS. The HDFS block size is 256 MB and the replication factor is 3. Each node runs 4 O/A (or Map/Reduce) concurrent tasks for DataMPI (or Hadoop).
-
Result: Compared with Hadoop, the performance improvement of DataMPI ranges from 30% to 52%.
Copyright (C) 2011-2014, DataMPI team
